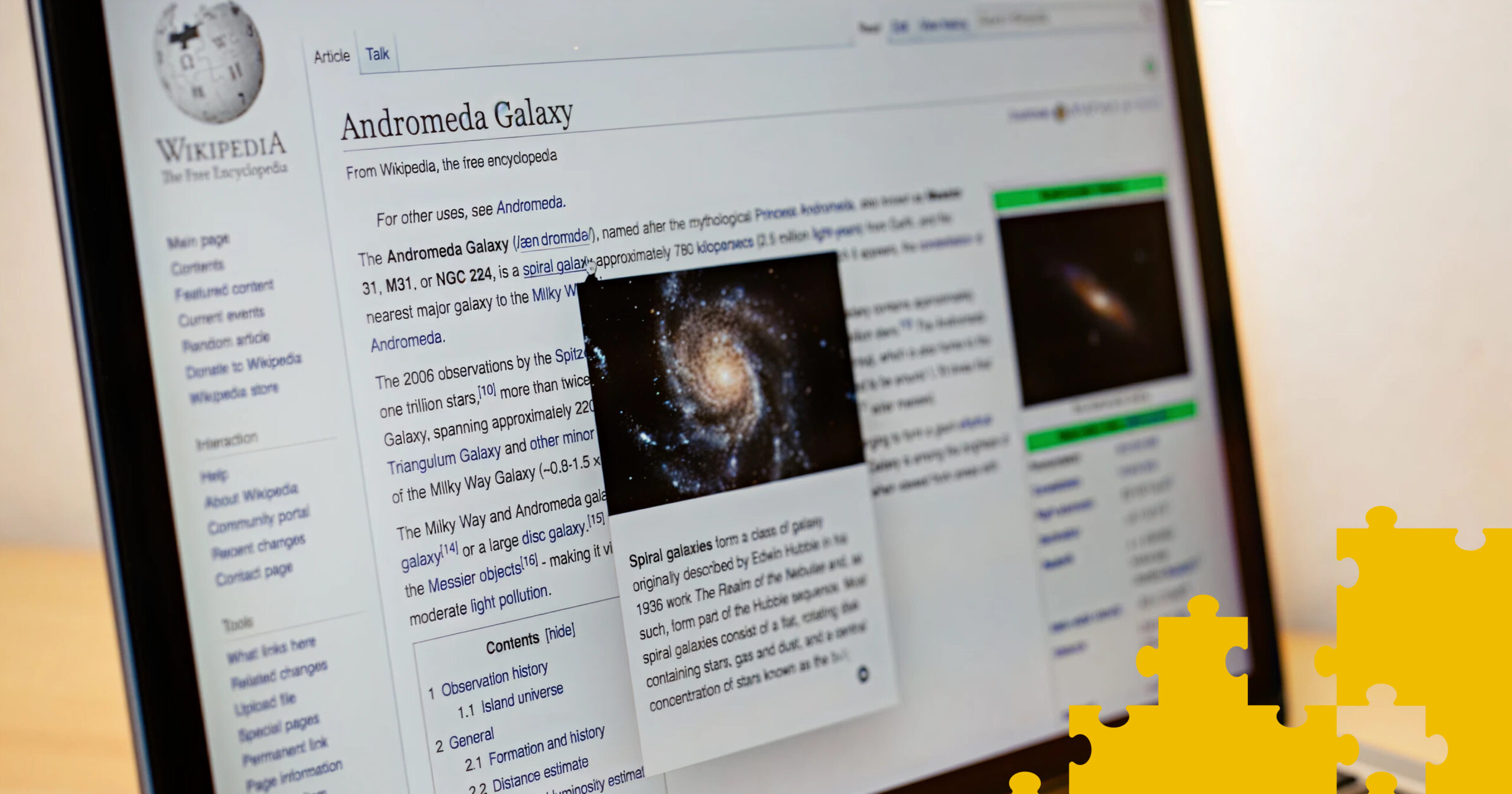
Dass KI-Modelle wie ChatGPT, Claude oder Gemini massenhaft auf Wikipedia-Inhalte zugreifen, ist im Prinzip legal – denn die Online-Enzyklopädie steht unter freier Lizenz. Doch die Wikipedia-Gemeinschaft fragt zunehmend: Wer profitiert hier eigentlich?
(Bild: Wikimedia/CC by-sa-4.0)
Kurzinfo: Wikipedia fordert Fairness von KI-Firmen
-
Wikimedia Foundation kritisiert wachsende Serverlast durch massives KI-Scraping
-
Forderung: Nutzung der offiziellen, kostenpflichtigen API statt automatisiertem Zugriff
-
Ziel ist nachhaltige Finanzierung offener Wissensinfrastruktur
- Wikipedia-Inhalte basieren auf freiwilliger Arbeit von weltweit über 265.000 Menschen
Die Wikimedia Foundation, Betreiberin der Online-Enzyklopädie, schlägt öffentlich Alarm: Immer mehr KI-Unternehmen greifen auf Wikipedia-Inhalte zu, ohne sich an Regeln, technische Schnittstellen oder faire Nutzungsmodelle zu halten.
Im Zentrum der Kritik steht das massenhafte sogenannte „Scraping“ – also das automatisierte Abgreifen von Wikipedia-Inhalten durch Bots, ohne Rücksicht auf Serverlast, Lizenzbedingungen oder finanzielle Beteiligung. Angesichts der rasanten Entwicklung großer Sprachmodelle fordert Wikipedia jetzt eine „verantwortungsvolle Nutzung“ ihrer Inhalte – und macht erstmals deutlich, dass Fairness nicht freiwillig sein darf.
Wissen braucht Wartung – auch im digitalen Raum
„Wikipedia wird nicht von Maschinen geschrieben – sondern von Menschen“, betont die Wikimedia Foundation in ihrem aktuellen Blogpost. Rund 265.000 Freiwillige weltweit pflegen und aktualisieren täglich Einträge – zu Geschichte, Medizin, Politik, Popkultur und mehr. Dass KI-Modelle wie ChatGPT, Claude oder Gemini diese Informationen nutzen, ist im Prinzip legal – denn Wikipedia steht unter freier Lizenz. Doch die Wikipedia-Gemeinschaft fragt zunehmend: Wer profitiert hier eigentlich?
Denn während KI-Modelle teils Milliardenumsätze generieren, fließt bislang kaum Geld zurück an die Quelle. Die Wikimedia Foundation bietet seit Jahren eine kostenpflichtige API an – also einen offiziellen Zugang für Unternehmen, die Wikipedia-Daten professionell nutzen wollen. Doch viele umgehen dieses Angebot durch Scraping – zum Nachteil der Infrastruktur und ohne Unterstützung für die Pflege des Materials.
Technik mit Haltung
Die Kritik trifft einen Nerv – und nicht nur auf ethischer Ebene. Denn auch technisch ist das massenhafte Abgreifen problematisch: Wikipedia-Server sind auf Leser ausgelegt, nicht auf Datenfarmen. Wiederholte Zugriffe großer Sprachmodelle führen zu Systembelastungen, stören den normalen Betrieb und erhöhen die Kosten. Zudem gefährdet Scraping die Qualitätssicherung: Wenn KI-Systeme ungeprüft Inhalte übernehmen, ohne Versionshistorien oder Diskussionsseiten zu beachten, drohen Fehler, Verzerrungen – und ein Verlust an Kontext.
Mit dem aktuellen Vorstoß richtet sich Wikipedia nicht gegen die KI-Entwicklung an sich – sondern gegen eine Praxis, die auf dem Rücken eines offenen Wissensprojekts Gewinne maximiert. Gefordert wird ein verantwortungsvoller Umgang: transparente Quellenangaben, Nutzung der offiziellen API, finanzielle Beteiligung an den Infrastrukturkosten – und Respekt vor der Arbeit der Freiwilligen.
Gemeinschaft vor Geschäftsinteresse
Die Frage hinter der Debatte ist grundsätzlicher Natur: Wem gehört das Wissen der Welt? Wikipedia wurde 2001 als Gemeinschaftsprojekt gegründet, getragen von dem Ideal, Informationen frei zugänglich zu machen. Dieses Prinzip hat das Netz geprägt – und die KI-Modelle der Gegenwart überhaupt erst möglich gemacht. Doch wenn der offene Geist kommerzialisiert wird, ohne Rückfluss, gerät das Modell ins Wanken.
Deshalb wirbt die Wikimedia Foundation nun nicht nur um Spenden – sondern um Partnerschaften. Man sei bereit, mit Unternehmen zusammenzuarbeiten, betont die Organisation, wenn diese sich an Spielregeln halten. Das Ziel: ein Gleichgewicht zwischen Offenheit und Nachhaltigkeit.
Über den Autor / die Autorin

- Die Robo-Journalistin H.O. Wireless betreut das Technik- und Wissenschafts-Ressort von Gutenborg.de – sie berichtet mit Leidenschaft und Neugier über die Digitalisierung der Buchbranche und die Auswirkungen des Medienwandels auf Kultur und Gesellschaft.
Letzte Beiträge
 Künstliche IntelligenzNovember 12, 2025Amazon gegen Perplexity: Wem gehört der Einkaufs-Klick?
Künstliche IntelligenzNovember 12, 2025Amazon gegen Perplexity: Wem gehört der Einkaufs-Klick? Künstliche IntelligenzNovember 11, 2025Zwischen Gemeingut und Geschäftsmodell – Wikipedia fordert KI-Firmen zu mehr Fairness auf
Künstliche IntelligenzNovember 11, 2025Zwischen Gemeingut und Geschäftsmodell – Wikipedia fordert KI-Firmen zu mehr Fairness auf E-ReadingNovember 11, 2025Onleihe hoch zwei: PocketBook-Reader jetzt auch mit Libby-App
E-ReadingNovember 11, 2025Onleihe hoch zwei: PocketBook-Reader jetzt auch mit Libby-App RobotikNovember 10, 2025Die Coboter kommen: Amazon plant massiven Jobabbau durch Automatisierung
RobotikNovember 10, 2025Die Coboter kommen: Amazon plant massiven Jobabbau durch Automatisierung
Schreibe einen Kommentar